ComfyUI für Einsteiger&Fortgeschrittene Tipps, Tricks, Austausch
Hallo liebe Gully-Mitbewohner,
wie angekündigt, kommt hier nun meine kleine Einsteiger-Anleitung für ComfyUI – praxisnah, verständlich und ohne unnötiges Blabla.
Wichtig: Ich setze Grundwissen oder zumindest das aufmerksame Lesen und Verstehen meiner Anleitung als Voraussetzung für diesen Thread voraus.
Hier geht’s nach dem Einstieg weiter – also bitte keine Fragen wie „Was ist ComfyUI?“ oder „Wie installier ich das?“.
Das steht alles sauber im Tutorial.
[ Link nur für registrierte Mitglieder sichtbar. Bitte einloggen oder neu registrieren ]
Und jetzt: Bühne frei – ich freu mich auf Austausch, Tipps & Fragen!
ich fange mal an mit dem Ksampler und erklär den mal genauer.
Was ist der KSampler?
Der KSampler ist der Kern von ComfyUI, der aus dem zufälligen Rauschen Schritt für Schritt dein Bild erzeugt. Er verarbeitet deinen Seed, die Anzahl der Schritte, CFG und den gewählten Sampler, um dein finales Bild zu backen.
Je nach Sampler ändert sich Stil, Schärfe und Details – er ist also der wichtigste Hebel, um deine Bilder zu steuern.
Kurz: Der KSampler macht aus „Chaos“ dein fertiges Bild.
Von oben nach unten:
1. Seed
„Welcher Zufall soll passieren?“
Eine Zahl, die den Zufallsstartpunkt für dein Bild vorgibt.
Gleiche Seed = gleiches Bild (wenn alles andere auch gleich ist).
-1 bedeutet: Mach jedes Mal ein neues Bild – also jedes Mal anders.
???? Tipp: Wenn dir ein Bild gefällt – schreib dir den Seed auf!
2. Control After Generate
"Was passiert beim nächsten Bild?"
randomize ? Jedes Mal ein komplett neuer Seed ? neue Ergebnisse.
fixed ? Immer derselbe Seed ? gleiches Bild, perfekt zum Testen.
increment ? Seed +1 bei jedem Run ? ähnliche Varianten.
decrement ? Seed -1 bei jedem Run ? rückwärts durch Varianten.
???? Tipp: Nutze „fixed“ zum Vergleichen, „randomize“ zum Rumspielen.
3. Steps
„Wie lange soll am Bild gearbeitet werden?“
Das sind die Rechenschritte – quasi: Wie oft wird das Bild überarbeitet.
Mehr Steps = mehr Details, aber auch mehr Rechenzeit.
Zu viele Steps können’s überladen machen.
Standardwerte:
SD 1.5: 20–30
SDXL: 30–50
4. CFG (Prompt-Stärke)
„Wie sehr soll sich das Bild an deinen Text halten?“
Niedrig = das Bild hat mehr Freiheit
Hoch = das Bild hält sich streng an deinen Prompt
Zuviel = es wirkt gekünstelt oder unnatürlich
Guter Startwert: 7–8
– darunter wird’s kreativ, darüber wird’s manchmal starr oder komisch.
5. Sampler Name
„Wie genau wird das Bild aus dem Rauschen gebaut?“
Unterschiedliche Methoden – denken wie „Stile der Bildentwicklung“.
Gute Allrounder:
Euler a = schnell, oft kantiger
DPM++ 2M Karras = weich, realistisch
Für Anfänger:
Starte mit DPM++ 2M Karras ? funktioniert fast immer gut.
6. Scheduler
„Wie wird die Zeit beim Bildaufbau eingeteilt?“
Legt fest, in welchem Takt die Steps ablaufen
Gute Kombis zum Sampler:
Wenn du „Karras“ im Namen hast ? nimm Karras auch hier.
Einfach merken:
Sampler mit Karras ? Scheduler auch Karras
7. Denoise
„Wie stark soll das Startbild verändert werden?“
Wert zwischen 0 und 1
1.0 = komplettes Bild aus Rauschen neu bauen
0.3 = nur leicht verändern (gut für Bild-Variationen)
Standardwert: 1.0
Wenn du auf ein bestehendes Bild arbeitest ? 0.3–0.6 je nach gewünschtem Effekt.
10 KSampler & ComfyUI Tipps
1. Seed aufschreiben!
Merke dir den Seed und die Einstellungen, wenn ein Bild richtig gut ist – so kannst du es jederzeit wiederholen oder variieren.
2. CFG nicht zu hoch drehen
Werte über 10 machen das Bild oft unnatürlich. Bleib zwischen 7 und 9 für bessere Balance.
3. Sampler & Scheduler passen zusammen
Nimm immer Kombis, die zusammengehören, z.?B. „DPM++ 2M Karras“ mit Scheduler „Karras“. Das sorgt für stabile Ergebnisse.
4. Mehr Schritte bringen nicht immer mehr Qualität
Über 30 Schritte (bei SD1.5) oder 50 (bei SDXL) sind oft Zeitverschwendung. Lieber öfter neu starten als ewig warten.
5. Varianten mit Seed-Modus „increment“ machen
Willst du ähnliche Bilder mit kleinen Unterschieden, stell „increment“ beim Seed ein und generiere mehrfach.
6. Denoise clever einstellen
Beim Verändern von Bildern hilft ein Denoise-Wert zwischen 0,3 und 0,6 – so bleibt das Grundbild erhalten, es wird nur leicht verändert.
7. CFG senken bei zu starken Prompts
Wenn das Bild komisch wird, probier mal den CFG-Wert runter, etwa auf 6 oder 7 – oft wirkt es dann natürlicher.
8. Mit Seed und Denoise experimentieren
Gleicher Text, verschiedene Seeds und Denoise-Werte zwischen 0,5 und 0,7 bringen oft kreative Variationen.
9. Sampler wechseln bei schlechten Ergebnissen
Wenn das Bild unscharf oder matschig wirkt, probier einen anderen Sampler aus – oft verbessert das die Qualität.
10. Nur eine Einstellung pro Änderung anpassen
Ändere nicht alles auf einmal, sonst weißt du nicht, was wirklich den Unterschied macht. Schritt für Schritt vorgehen.
BTW: Sollten keine Fragen kommen, werde ich versuchen, mind. alle zwei Tage mein Wissen zu teilen.
__________________
"Gibst du einem Mann einen Fisch, so ernährst du ihn für einen Tag. Erschlägst du den Mann aber mit einem Stock, so bekommst du nicht nur den Fisch, sondern auch seine Frau!"
Link down? PM! Re-Up kommt!
Geändert von GrowJoe (01.08.25 um 10:29 Uhr)
Grund: Link zur neuen version geändert
Die folgenden 4 Mitglieder haben sich bei GrowJoe bedankt:
Rückfrage, da ich es tatsächlich länger nicht mehr nutze - dein verlinkter Screenshot sieht ähnlich der Variante aus, die lokal zu installieren war. Sieht also entweder die Webapp von denen genauso aus, haben sie keine oder wäre es nicht irgendwie klüger gewesen, im ersten Schritt die Installation und die Besonderheiten einer lokalen Nutzung hervorzuheben?
Da ich gerade Zeit habe, will ich gerne noch erläutern, was Promps sind und wie man sie richtig nutzt und schreibt.
Prompt = Wunschvorstellung fürs Bild
Beispiel:
a woman sitting on a balcony, wearing a summer dress, sunset, cinematic lighting
Das bedeutet: Ich will eine Frau, die auf einem Balkon sitzt, ein Sommerkleid trägt, die Szene spielt bei Sonnenuntergang und das Licht soll aussehen wie im Kino.
So schreibst du gute Prompts
Starte mit dem Hauptmotiv
Was soll im Mittelpunkt stehen? Mensch, Tier, Objekt, Ort?
Beispiel:
a young woman, 20 years old, short hair
Füge Details hinzu
Was trägt die Person? Was macht sie? Wie ist die Stimmung?
Beispiel:
sitting at a desk, writing in a journal, cozy atmosphere
Stichworte für Bildstil
Willst du, dass das Bild realistisch aussieht? Oder eher wie ein Anime, Gemälde, 3D-Render?
Beispiel:
photo-realistic, soft light, shallow depth of field
Umgebung und Zeit
Tagsüber? Draußen? Drinnen? Sommer, Winter?
Beispiel:
evening light, modern living room, autumn
Keine ganzen Sätze
Die KI braucht keine Grammatik – Stichworte reichen. Also nicht:
"Ich möchte gerne eine Frau sehen, die…"
Sondern lieber:
woman, smiling, sitting in a kitchen, morning sunlight
Prompt-Optimierung
Wichtige Begriffe zuerst, weniger wichtige danach
Nutze Kommata, um Begriffe zu trennen
Wenn du was verstärken willst, geht das mit doppelten Klammern:
((beautiful face)), (soft lighting)
Negative Prompts
Damit sagst du der KI, was NICHT passieren soll
Beispiel:
blurry, distorted face, extra limbs, bad anatomy
Das sorgt für saubere Bilder
Hier ein paar Beispiele: hier wurde ein schlechter Prompt verwendet. Einfach nur "woman, balcony, sun, face" ohne negative Promps.
Bessere Promps mit negative Promps: "portrait, young woman, 25 years old, sitting alone, small city balcony, golden hour, soft natural sunlight, warm highlights on skin, loose light grey knit sweater, messy bun, melancholic expression, gazing into distance, soft breeze, strands of hair moving, cinematic atmosphere, ((bokeh background)), ambient shadows, emotional mood, shallow depth of field, warm color grading, 35mm photo"
Negative Promps: "bad anatomy, blurry, out of frame, low resolution, poorly drawn face, extra fingers, overexposed, unrealistic eyes, cartoon, painting"
Sehr schön, nun weißt du wie man promps nutzt. Sei gespannt auf die nächste übrung
Kleine Kritik in eigener Sache: Ich hab das hier alles 5mal schreiben dürfen, weil CENCORED..das war doch früher nie so, kann man das nicht ändern wieder? Es nervt nur noch.
__________________
"Gibst du einem Mann einen Fisch, so ernährst du ihn für einen Tag. Erschlägst du den Mann aber mit einem Stock, so bekommst du nicht nur den Fisch, sondern auch seine Frau!"
Link down? PM! Re-Up kommt!
..wäre es nicht irgendwie klüger gewesen, im ersten Schritt die Installation und die Besonderheiten einer lokalen Nutzung hervorzuheben?
Das ist die Lokale Nutzung. Man kann alles über die CMD Eingabe installieren, was mir aber zu kompliziert erschien, daher suchte ich einen fertigen Installer raus. Es ist aber genau das selbe, sogar besser, da schon der Manager vorinstalliert sind.
Gern mach ich aber eine CMD Installation noch dazu.
Du brauchst nur eine frische Python-Installation (am besten 3.10.x), Git und eine Internetverbindung. Ich geh davon aus, du machst das auf Windows.
1. Ordner wählen (z.?B. C:\ComfyUI):
cd C:\
mkdir ComfyUI
cd ComfyUI
2. Repository klonen:
git clone [ Link nur für registrierte Mitglieder sichtbar. Bitte einloggen oder neu registrieren ]
cd ComfyUI
– Lade model.ckpt (z.?B. SD 1.5 oder ein anderes Checkpoint) und speichere ihn in:
ComfyUI\models\checkpoints\
Optional: VAE in ComfyUI\models\vae\ und LoRA oder Textual Inversion entsprechend in ihre Ordner.
6. ComfyUI starten:
python main.py
Kann sein, dass ich deine Frage grad falsch verstehe.
__________________
"Gibst du einem Mann einen Fisch, so ernährst du ihn für einen Tag. Erschlägst du den Mann aber mit einem Stock, so bekommst du nicht nur den Fisch, sondern auch seine Frau!"
Link down? PM! Re-Up kommt!
ICH weiß, wie man das installiert. Aber du wolltest einen Anfänger Guide schreiben und veröffentlichen, und für einen Anfänger ist es ja erstmal relevant, wie man das überhaupt auf den eigenen Rechner bekommt, was man benötigt usw.
Und die Anleitung, die du nun gepostet hast, ist halt auch 0 für Anfänger geeignet. Dazu fehlt ja alles, was relevant ist, an infos, womit/worüber es überhaupt betrieben werden kann/soll. Welche Hardware ist nötig, welche Software, was muss man beachten, wo liegen Risiken usw.
DAS alles würde einen Guide ausmachen. Deshalb habe ich auch so lange nichts zu gesagt, weil mir klar war, dass genau das eben nicht kommt, sondern eine Anleitung, wie man es nutzt, sofern man weiß, was man wie vorher zu tun gehabt hat. Meine das nicht böse, aber ist halt immer wieder das selbe. Das wesentlichste, was es zu einem Guide machen würde, fehlt.
Ich hatte in einem anderen Thread die erste Version der Anleitung gepostet – mit der Bitte, sie mal zu laden und mir Feedback zu geben. Du hast den Thread offenbar auch gelesen, hättest also die Anleitung anschauen und mir kurz Rückmeldung geben können – hast du aber nicht.
Jemand anderes hat mir dann geantwortet und meinte, das Ganze sei auch für Newbies verständlich. Daher bin ich davon ausgegangen, dass das Thema erledigt ist.
Jetzt weiß ich Bescheid – und passe es gern an.
PS: Die Anleitung basiert auf einer .exe, die alles automatisch installiert – Python, Git, ComfyUI und alle Abhängigkeiten. Eine manuelle Installation ist darin nicht nötig und wird deshalb auch nicht im Detail erklärt. Wenn gewünscht, kann ich das aber ergänzen.
Edit: Neue Version der Anleitung ist raus.
__________________
"Gibst du einem Mann einen Fisch, so ernährst du ihn für einen Tag. Erschlägst du den Mann aber mit einem Stock, so bekommst du nicht nur den Fisch, sondern auch seine Frau!"
Link down? PM! Re-Up kommt!
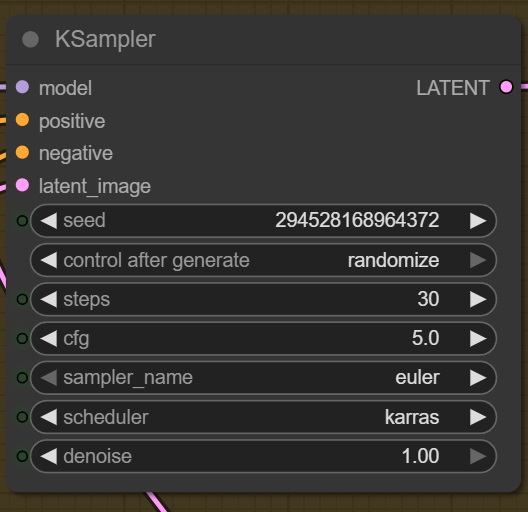
Heute geht’s ans Eingemachte – Checkpoints in ComfyUI.
Checkpoints in ComfyUI
Sie sind das Fundament deiner Bild-Ästhetik.
Ein Checkpoint ist im Grunde deine gesamte Bildsprache und Stilrichtung in einem kompakten KI-Modell. Technisch basiert das auf vortrainierten Netzwerken – meist in speziellen Dateiformaten.
Die „Checkpoint Loader“-Node lädt dieses Modell. Schon durch das Wechseln des Checkpoints verändert sich die komplette Bildwirkung – selbst wenn der Text gleich bleibt.
Beispiele:
realisticVision = hyperrealistisch
revAnimated = stylisierte Anime-Realität
dreamshaper = episch & weich
deliberate = vielseitig & emotional
Details findest du in der Anleitung.
Meine Checkpoints lade ich zu 90?% von folgender Webseite:
[ Link nur für registrierte Mitglieder sichtbar. Bitte einloggen oder neu registrieren ]
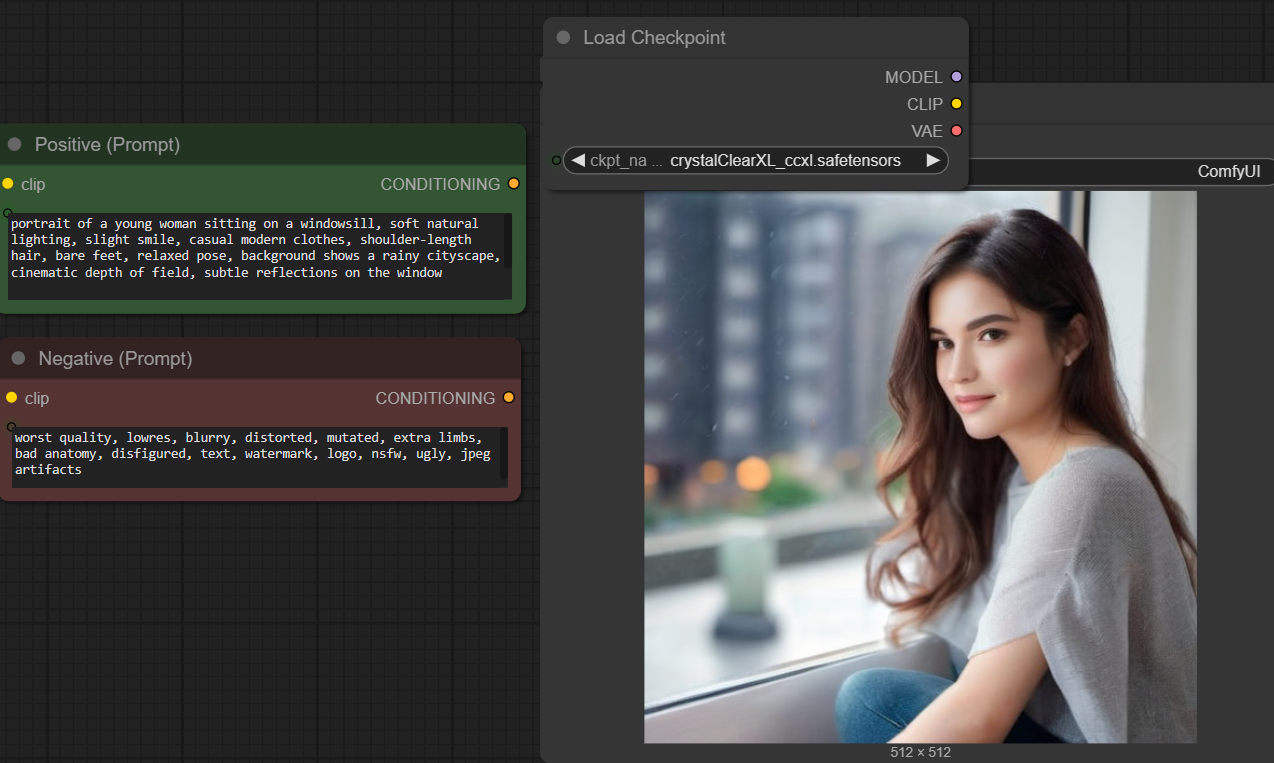
Und da Bilder mehr sagen als Worte:
Wir sehen hier ein Ergebnis, gemacht mit crystalClearXl.safetensors
[ Link nur für registrierte Mitglieder sichtbar. Bitte einloggen oder neu registrieren ]
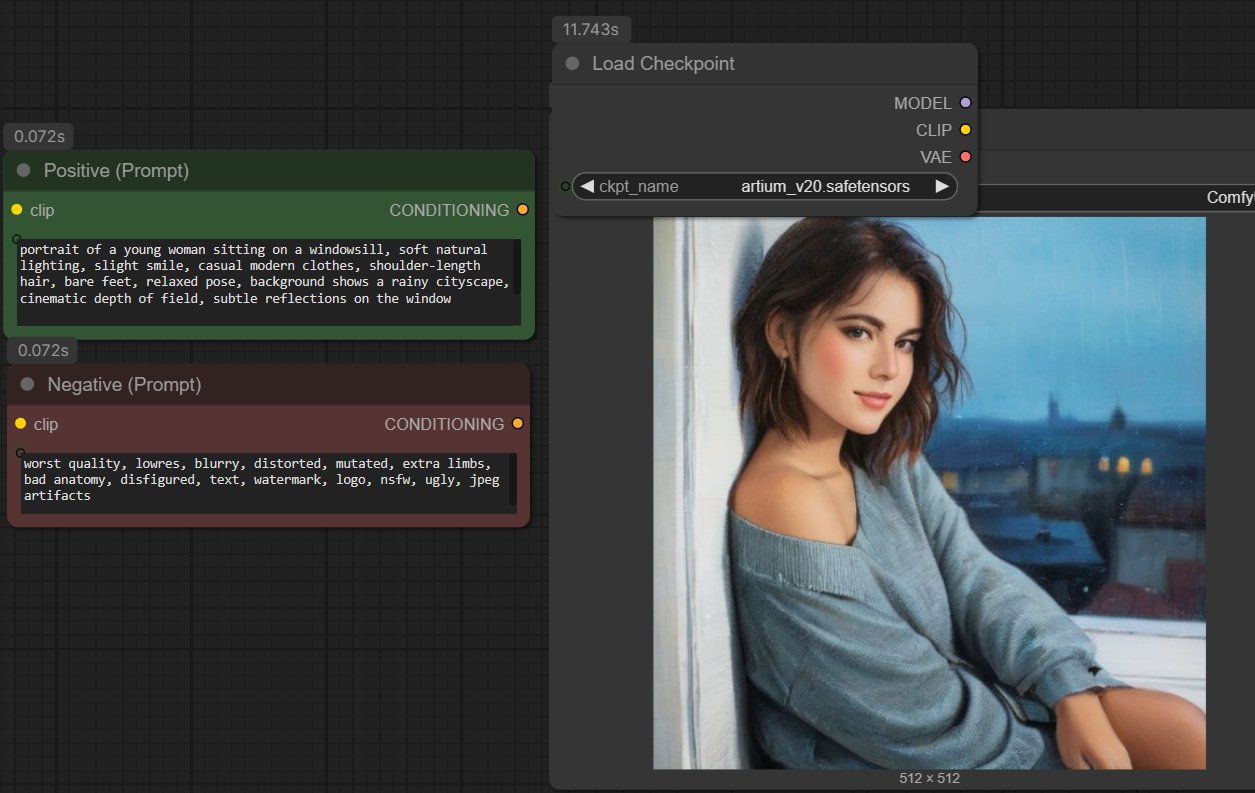
Und hier ein Bild mit denselben Einstellungen, aber mit dem Checkpoint Artium v2
BITTE BEACHTEN!!!
Die Bilder sind jetzt nicht auf „schön“ getrimmt.
Tipp:
Vergleiche gleiche Prompts mit unterschiedlichen Checkpoints.
So findest du deinen Stil.
Kombiniere mit Loras, um gezielt Aspekte reinzumixen (z.?B. bessere Hände, spezifische Kleidung, bestimmte Gesichter).
(Kommt als Nächstes)
Wichtig:
RAM-Killer: Große Checkpoints (z.?B. 2.2?GB) ballern schnell deinen VRAM voll.
Nicht jeder VAE passt zu jedem Modell – achte auf Kompatibilität, dazu später mehr.
__________________
"Gibst du einem Mann einen Fisch, so ernährst du ihn für einen Tag. Erschlägst du den Mann aber mit einem Stock, so bekommst du nicht nur den Fisch, sondern auch seine Frau!"
Link down? PM! Re-Up kommt!
Die folgenden 3 Mitglieder haben sich bei GrowJoe bedankt:
moin moin, nur mal eine verständnis frage - kann ich in ComfyUI auch meine eigenen bilder hochladen - denn leider sind die bilder in chatgpt und copilot und andere wegen urheberschutz nie so wie das bild wirklich ist ...
moin moin,.. frage - kann ich in ComfyUI auch meine eigenen bilder hochladen...
Ja, das geht auch – dazu komme ich auch noch. Wenn ich es schaffe, sind heute die Loras an der Reihe. Für eigene Bilder braucht man am besten einen anderen Workflow – am besten einen, der auf Flux basiert.
Wenn du es aber schnell brauchst, dann starte ComfyUI. Dort gehst du oben links auf Workflow > Browse Template, klickst in der linken Spalte auf Flux und nimmst dort das erste: „Flux Content Dev“.
Mein Hund und ich von einem Foto übernommen.
__________________
"Gibst du einem Mann einen Fisch, so ernährst du ihn für einen Tag. Erschlägst du den Mann aber mit einem Stock, so bekommst du nicht nur den Fisch, sondern auch seine Frau!"
Link down? PM! Re-Up kommt!
Die folgenden 3 Mitglieder haben sich bei GrowJoe bedankt:
Zurzeit fehlt mir leider die Zeit… öhm, als Nächstes wäre eigentlich LoRA dran. Ich hab schon einiges vorbereitet, AABER das Ganze in eine Anleitung zu packen, ist deutlich schwerer als gedacht Am besten, ihr fragt einfach nach, falls ihr Interesse an all dem habt.
Ich hau euch hier mal das rein, was ich bisher zu LoRA habe. Es ist zwar noch nicht ausgearbeitet und vielleicht an manchen Stellen etwas schwer zu verstehen, aber ich will’s euch trotzdem nicht vorenthalten.
Was zur Hölle ist ’ne LoRA?
Stell dir vor, dein Base Model (Checkpoint) ist ein neutraler Allround-Koch. Der kann alles irgendwie, aber nix mit Charakter.
Eine LoRA ist wie ’n spezielles Gewürzglas: klein, leicht, und ballert gezielt Stil, Inhalt oder Details in dein Bild – ohne dass du gleich ein 7-GB-Monster neu trainieren musst.
Mit LoRA kannst du:
’nen bestimmten Kunststil reinknallen (z. B. Aquarell, Tinte, Cyberpunk)
Charaktereigenschaften hinzufügen (z. B. Game-Charaktere, Schauspieler, Anime-Figuren)
Stimmung ändern (z. B. düster, romantisch, Regenwetter)
Vorteil: LoRAs sind klein (50–200 MB), brauchen wenig Leistung und lassen sich stapeln wie Lego.
Ordnerstruktur (sonst findet ComfyUI nix)
????ComfyUI
??? ????models
? ??? ????checkpoints
? ? ??? ????SD1.5 // Base Models (z. B. DreamShaper v hier rein
? ??? ????loras
? ??? ????SD1.5 // LoRAs (z. B. MoXin, QingYi) hier rein
Regel Nr. 1: LoRA muss zum Modelltyp passen!
SD1.5-LoRA auf SD1.5, SDXL-LoRA auf SDXL. Wenn du das mischst, sieht’s aus wie ein Unfall.
Dateinamen anpassen:
moxin.safetensors ? MoXin_AsianStyle_v1.0.safetensors ? später keine Sucherei.
Der LoRA Loader Node
Das Herzstück.
Der LoRA Loader scannt automatisch alles, was im ComfyUI/models/loras-Ordner liegt (inkl. Unterordner).
Du musst nur auswählen, welche LoRA du willst – ComfyUI macht den Rest.
Inputs (was du anschließt):
model (MODEL) ? dein Base Model (z. B. DreamShaper)
clip (CLIP) ? dein CLIP-Encoder (kommt meist aus dem Checkpoint Loader)
lora_name (COMBO[STRING]) ? Drop-Down zum Auswählen deiner LoRA
strength_model (FLOAT) ? wie stark die LoRA das Bild-Rendering beeinflusst (0–1 normal, darüber Hardcore)
strength_clip (FLOAT) ? wie stark die LoRA die Prompt-Interpretation beeinflusst (0–1 normal)
Outputs (was rauskommt):
model (MODEL) ? dein Base Model mit LoRA-Änderungen
clip (CLIP) ? dein CLIP mit LoRA-Änderungen
Mehrere LoRAs laden
Einfach mehrere LoRA Loader Nodes hintereinander hängen – jeder lädt eine andere LoRA.
So kannst du z. B. erst einen bestimmten Zeichenstil laden und danach ’ne LoRA, die die Haut realistisch macht.
Gewichte verstehen (Strength)
0.1–0.3 = nur leichter Hauch vom Stil
0.5 = halber Einfluss
1.0 = voller Stil
>1.0 = übertreiben (geht, aber kann komisch aussehen)
Tipp: Willst du einen Charakter wiedererkennen ? Gewicht hoch.
Willst du nur Stimmung oder Hintergrund ändern ? Gewicht runter.
LoRA im Prompt
Manche LoRAs wirken nur durchs Laden, andere wollen im Prompt erwähnt werden:
<lora:MoXin:1> a beautiful asian woman, wearing traditional dress
<loraateinameOhneEndung:Gewicht> ? Name exakt wie Datei (ohne .safetensors).
Warum LoRA so praktisch ist
Flexibel ? Schnell Stile wechseln ohne neues Modell
Effizient ? Wenig Speicher, wenig Rechenpower nötig
Kombinierbar ? Mehrere LoRAs für komplexe Ergebnisse
K-Sampler & Steps für Tests
Steps: 20–30 reichen
Sampler: Euler a oder DPM++ 2M Karras ? stabil und schnell
Seed fixieren, wenn du Unterschiede testen willst
noob-Fehler vermeiden
LoRA passt nicht zum Modelltyp ? Matschbild
Name im Prompt falsch ? LoRA tut nix
5 LoRAs mit Gewicht 1.0 ? KI kotzt
strength_model und strength_clip beide zu hoch ? Bild sieht künstlich aus
LoRA = kleiner Filter mit großem Einfluss
Sauber installieren, richtig anschließen, Gewicht im Griff behalten
Mit Prompts & Negatives zusammen nutzen ? Profi-Ergebnisse
Nicht denken „mehr ist besser“ – oft killt’s nur den Look
Wo du LoRA-Modelle (für Stable Diffusion & Co.) herunterladen kannst:
1. CivitAI
Der absolute Klassiker unter den LoRA-Model-Shops. Einfach auf der Website den Filter auf „LoRA“ setzen – zack, schaust du sofort nur LoRA-Modelle an. Riesen Auswahl!
Eine der größten Open-Source-Communities überhaupt – dort findest du auch LoRA-Modelle, zwar nicht so viele wie bei CivitAI, aber eine vielfältige Auswahl.
Alternative Plattform mit einer ordentlichen Sammlung. Nutzer:innen berichten auch, dass manche LoRAs dort auftauchen, die auf CivitAI nicht mehr verfügbar sind.
SeaArt.ai
4. GitHub / Entwickler-Hosting
Viele LoRA-Projekte, Tools und Modelle finden sich auf GitHub oder Entwicklerseiten – besonders hilfreich, wenn du etwas höchst Spezifisches oder experimentelles suchst.
5. PixAI.art
Marktplatz mit Fokus auf AI-Kunstmodelle. LoRA-Add-ons und ähnliche Sachen könnten vertreten sein – lohnt sich, da reinzuschnuppern.
PixAI.art
__________________
"Gibst du einem Mann einen Fisch, so ernährst du ihn für einen Tag. Erschlägst du den Mann aber mit einem Stock, so bekommst du nicht nur den Fisch, sondern auch seine Frau!"
Link down? PM! Re-Up kommt!






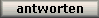






 hier wurde ein schlechter Prompt verwendet. Einfach nur "woman, balcony, sun, face" ohne negative Promps.
hier wurde ein schlechter Prompt verwendet. Einfach nur "woman, balcony, sun, face" ohne negative Promps.




 ansonsten warte ich gerne
ansonsten warte ich gerne
 hier rein
hier rein Linear-Darstellung
Linear-Darstellung